Exploring Apache Spark: Understanding the RDD
![]()
The Resilient Distributed Dataset (RDD)
Developed at UC Berkley in 2009 and eventually open-sourced to the Apache Foundation, Spark RDDs implement a novel method for data storage and processing that results in a hundred-fold speed increase over disk-reliant solutions such as MapReduce (speed-up varies depending upon the type of operation).
All of the gory details can be found in the original paper, Resilient Distributed Datasets, but the main advantages of the RDD approach can be summarized as:
1. In-Memory Processing
Using RAM while providing seamless spill-over to hard disk significantly boosts processing speed. Spark reduces slow disk IO and network communication. Spark can further speed-up jobs requiring repeated iterations over the same data (e.g. Logistic Regression or K-Means) by caching intermediate results in memory.
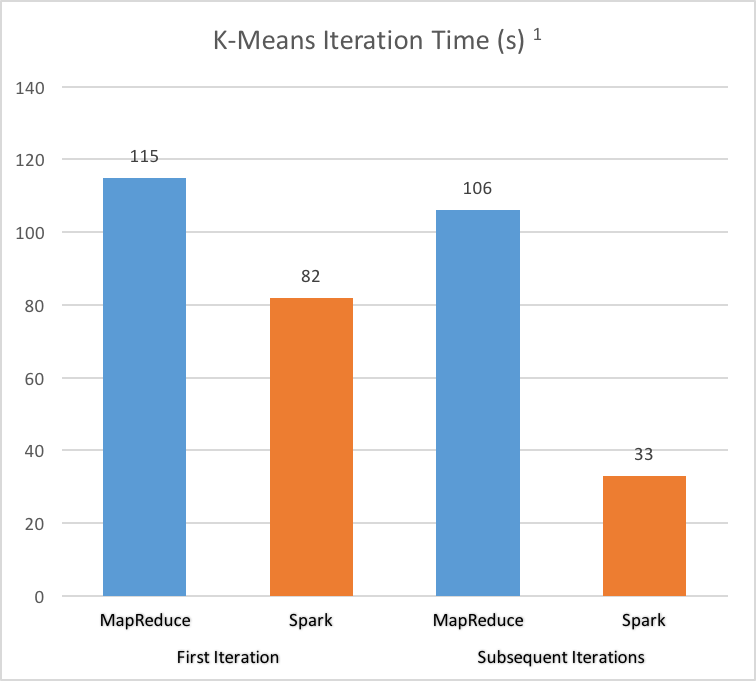
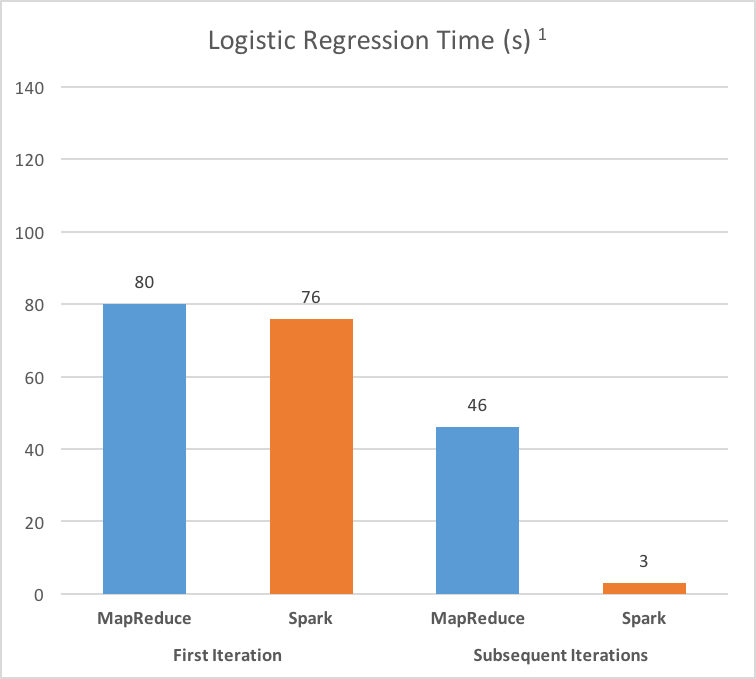
2. Lazy Execution and Lineage Graphing
When performing data transformations, rather than editing data in-place or occupying additional memory to store intermediate datasets, Spark only stores the series of functions applied to the data. As additional transformations are called, the lineage graph expands until its functions are lazily executed.
Since the original data remains unaltered in memory, fault recovery is as simple as re-applying the stored functions to the data that was affected by failure.
import org.apache.spark.{SparkConf, SparkContext}
// Setting up test data set
val conf = new SparkConf().setAppName("RddDemo").setMaster("local[8]")
val sc = new SparkContext(conf)
val numbersRdd = sc.parallelize(Seq(1, 2, 3, 4, 5, 6, 7, 8, 9))
// The commands below, called "transformations", are lazily executed
val squaresRdd = numbersRdd.map(n => Seq(n, n * n))
val allNumsRdd = squaresRdd.flatMap(tup => tup)
val sortedNum = allNumsRdd.sortBy(n => n)
At this point, despite calling functions to create 3 new RDDs in a chain of transformations, those functions have not been executed. Only our original dataset exists in memory, and the transformations await execution when necessary. The lineage graph of these functions forms a DAG (directed acyclic graph) representing the functions to be applied to the original dataset.
The DAG of transformation functions only executes when an action is performed. In Spark, actions are those RDD operations that result in an output that is not another RDD. Actions include reduce, collect, count, first, take, takeSample, countByKey, and saveAsTextFile.
// Calling "collect" on the RDD executes the sequence of transformations
// that had been stored until this point in a lineage DAG
val results = sortedNum.collect()
println(results.mkString(", "))
// Results: 1, 1, 2, 3, 4, 4, 5, 6, 7, 8, 9, 9, 10, 11, 12, 16, 25, 36, 49, 64, 81
This lazy-execution approach allows complex transformations to be chained together while maintaining the immutability of the original dataset and preventing unnecessary replication of data. In addition, all operations pertaining to an item in a dataset can be stream-lined, resulting in a lower context-switching overhead.
3. An Easy and Intuitive Programming Abstraction
The lineage graphing explanation above only scratches the surface of the complexity lurking beneath the hood of Spark. Despite that complexity, Spark presents a succinct and readable programming abstraction that allows transformations to be implemented in a fraction of the code of traditional MapReduce.
Below is example code for a simple WordCount program for Hadoop MapReduce written in Java taken from the Hadoop docs:
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.StringUtils;
public class WordCount2 {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
static enum CountersEnum { INPUT_WORDS }
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
private boolean caseSensitive;
private Set<String> patternsToSkip = new HashSet<String>();
private Configuration conf;
private BufferedReader fis;
@Override
public void setup(Context context) throws IOException,
InterruptedException {
conf = context.getConfiguration();
caseSensitive = conf.getBoolean("wordcount.case.sensitive", true);
if (conf.getBoolean("wordcount.skip.patterns", true)) {
URI[] patternsURIs = Job.getInstance(conf).getCacheFiles();
for (URI patternsURI : patternsURIs) {
Path patternsPath = new Path(patternsURI.getPath());
String patternsFileName = patternsPath.getName().toString();
parseSkipFile(patternsFileName);
}
}
}
private void parseSkipFile(String fileName) {
try {
fis = new BufferedReader(new FileReader(fileName));
String pattern = null;
while ((pattern = fis.readLine()) != null) {
patternsToSkip.add(pattern);
}
} catch (IOException ioe) {
System.err.println("Caught exception while parsing the cached file '"
+ StringUtils.stringifyException(ioe));
}
}
@Override
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
String line = (caseSensitive) ?
value.toString() : value.toString().toLowerCase();
for (String pattern : patternsToSkip) {
line = line.replaceAll(pattern, "");
}
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
Counter counter = context.getCounter(CountersEnum.class.getName(),
CountersEnum.INPUT_WORDS.toString());
counter.increment(1);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
GenericOptionsParser optionParser = new GenericOptionsParser(conf, args);
String[] remainingArgs = optionParser.getRemainingArgs();
if (!(remainingArgs.length != 2 | | remainingArgs.length != 4)) {
System.err.println("Usage: wordcount <in> <out> [-skip skipPatternFile]");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount2.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
List<String> otherArgs = new ArrayList<String>();
for (int i=0; i < remainingArgs.length; ++i) {
if ("-skip".equals(remainingArgs[i])) {
job.addCacheFile(new Path(remainingArgs[++i]).toUri());
job.getConfiguration().setBoolean("wordcount.skip.patterns", true);
} else {
otherArgs.add(remainingArgs[i]);
}
}
FileInputFormat.addInputPath(job, new Path(otherArgs.get(0)));
FileOutputFormat.setOutputPath(job, new Path(otherArgs.get(1)));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
That’s quite the wall of code. Here is the Apache Spark implementation using an RDD:
import org.apache.spark.{SparkConf, SparkContext}
object WordCount extends App {
val conf = new SparkConf().setAppName("WordCount").setMaster("local[8]")
val sc = new SparkContext(conf)
val inputPath = args(0)
val outputPath = args(1)
val words = sc.textFile(inputPath)
.flatMap(line => line.split(" "))
words.map(word => (word, 1))
.reduceByKey(_ + _)
.saveAsTextFile(outputPath)
}
Or if you really want to overdo it, those last 4 lines could be merged into one:
sc.textFile(args(0))
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.saveAsTextFile(args(1))
What’s Next?
As you’ve seen, RDDs are a powerful tool that has helped to make Apache Spark one of the hottest open-source projects. The combination of speed and ease of programming is hard to beat. RDDs aren’t ideal for every situation, though, and while they offer a simple programming interface for many tasks, they lack a lot of features that data scientists are used to working with.
Dataframes in R and Pandas in Python expose a different programming interface with additional flexibility. Spark DataFrames were developed to bring that functionality to Spark. In my next post, I’ll go over how they differ from basic RDDs, and show a few examples of how to work with them.
1) Execution times from Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing by Zaharia, et al.