(Part 2) Client Mode
This post covers client mode specific settings, for cluster mode specific settings, see Part 1.
In my previous post, I explained how manually configuring your Apache Spark settings could increase the efficiency of your Spark jobs and, in some circumstances, allow you to use more cost-effective hardware.
The configs I shared in that post, however, only applied to Spark jobs running in cluster mode. In cluster mode, the driver for a Spark job is run in a YARN container. This means that it runs on one of the worker nodes of the cluster.
The alternative to cluster mode is client mode. For more info about client mode vs cluster mode, see this Cloudera blogpost. There are pros and cons to both run modes, and they each have use-cases for which they are most appropriate.
For our purposes, though, the key difference is that the driver for a Spark job running in client mode runs on the master node of a cluster rather than one of the worker nodes. If we were to use our cluster mode configs while running in client mode, two problems potentially arise:
- Underused Worker Node - Our cluster mode configs set aside enough resources on one worker node for the driver. In client mode, those resources will go unused.
- Inability To Allocate Driver - Often, the master node of a cluster has significantly fewer resources than the worker nodes. If the Spark configs for the driver attempt to allocate more resources than the master node has available, Spark jobs will refuse to start.
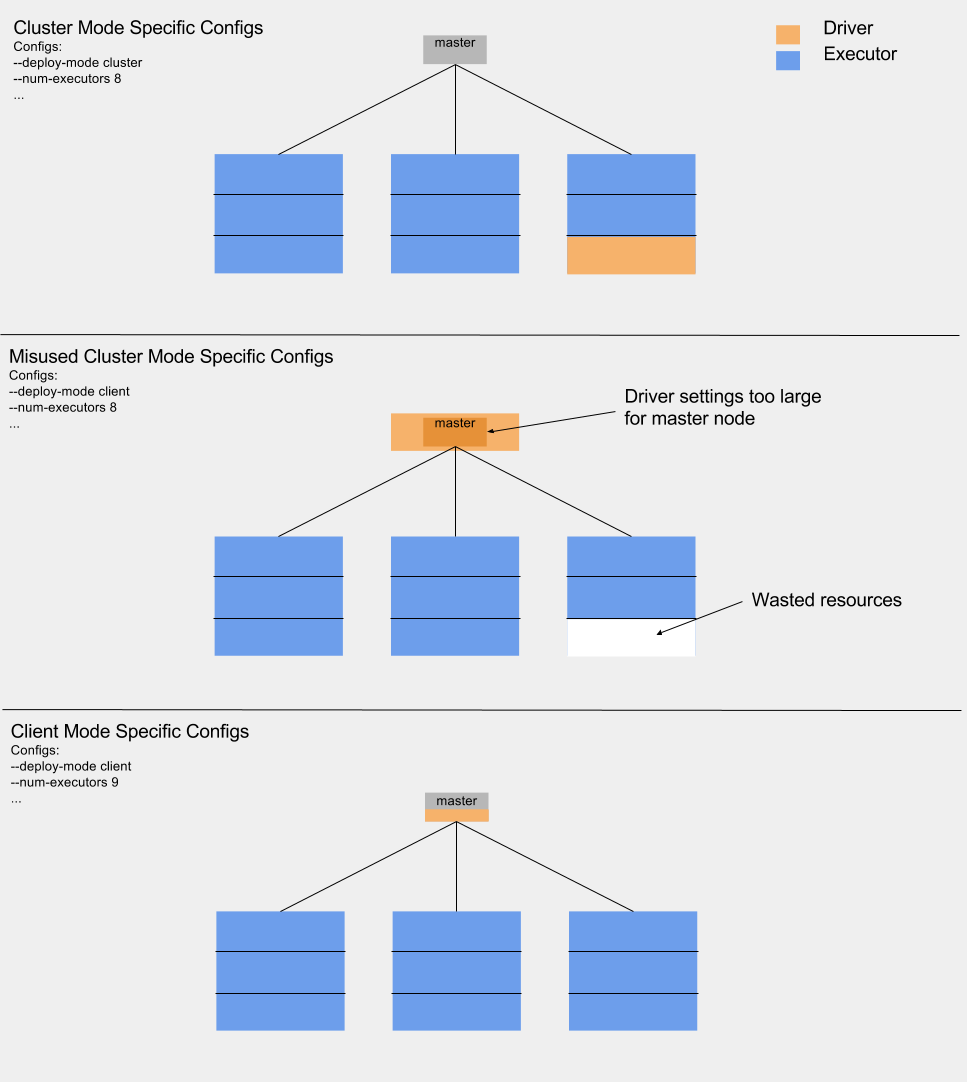
Fortunately, a few minor additions to our config cheatsheet can extend its usage to client mode as well. In a nutshell, those changes are:
- Increasing the executor number by one to utilize the resources on the worker node that had previously been reserved for the driver.
- Reducing the driver resources allocated by the configs so that the driver can be run on the master node.
I’ve added a new tab to the config cheatsheet that is client mode specific.

Below, I’ve detailed the different fields of the spreadsheet. There is some duplicate information here from the cluster mode post, but this should keep you from having to switch back and forth if you’re trying to configure a client mode cluster.
The client mode specific settings have been marked.
Apache Spark Config Cheatsheet - xlsx
Configurable Fields
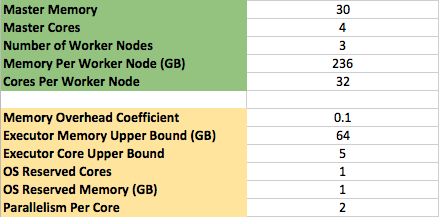
The fields shown above are configurable. The green-shaded fields should be changed to match your cluster’s specs. It is not recommended that you change the yellow-shaded fields, but some use-cases might require customization. More information about the default, recommended values for the yellow-shaded fields can be found in the Cloudera post.
Master Memory (Client Mode Specific)
The RAM available on your master node. This can be the entirety of the node’s available memory, or you can set it lower if you have other processes running on the master node.
Master Cores (Client Mode Specific)
The cores available on your master node. As with the memory, this can be all available cores, or it can be set to a lower number if other processes are running on the master node.
Number of Worker Nodes
The number of worker machines in your cluster. This can be as low as one machine.
Memory Per Worker Node (GB)
The amount of RAM per node that is available for Spark’s use. If using Yarn, this will be the amount of RAM per machine managed by Yarn Resource Manager.
Cores Per Worker Node
The number of cores per node that are available for Spark’s use. If using Yarn, this will be the number of cores per machine managed by Yarn Resource Manager.
Memory Overhead Coefficient
Recommended value: .1
The percentage of memory in each executor that will be reserved for spark.yarn.executor.memoryOverhead.
Executor Memory Upper Bound (GB)
Recommended value: 64
The upper bound for executor memory. Each executor runs on its own JVM. Upwards of 64GB of memory and garbage collection issues can cause slowness.
Executor Core Upper Bound
Recommended value: 5
The upper bound for cores per executor. More than 5 cores per executor can degrade HDFS I/O throughput. I believe this value can safely be increased if writing to a web-based “file system” such as S3, but significant increases to this limit are not recommended.
OS Reserved Cores
Recommended value: 1
Cores per machine to reserve for OS processes. Should be zero if only a percentage of the machine’s cores were made available to Spark (i.e. entered in the Cores Per Node field above).
OS Reserved Memory (GB)
Recommended value: 1
The amount of RAM per machine to reserve for OS processes. Should be zero if only a percentage of the machine’s RAM was made available to Spark (i.e. entered in the Memory Per Node field above).
Parallelism Per Core
Recommended value: 2
The level of parallelism per allocated core. This field is used to determine the spark.default.parallelism setting. Generally recommended setting for this value is double the number of cores.
Note: Cores Per Node and Memory Per Node could also be used to optimize Spark for local mode. If your local machine has 8 cores and 16 GB of RAM and you want to allocate 75% of your resources to running a Spark job, setting Cores Per Node and Memory Per Node to 6 and 12 respectively will give you optimal settings. You would also want to zero out the OS Reserved settings. If Spark is limited to using only a portion of your system, there is no need to set aside resources specifically for the OS.
Reference Table
Note: This section remains unchanged from the cluster mode version of the config cheatsheet. The process for selecting the best number of executors per node remains the same, but the way in which that selection is converted into Spark configuration settings differs slightly.
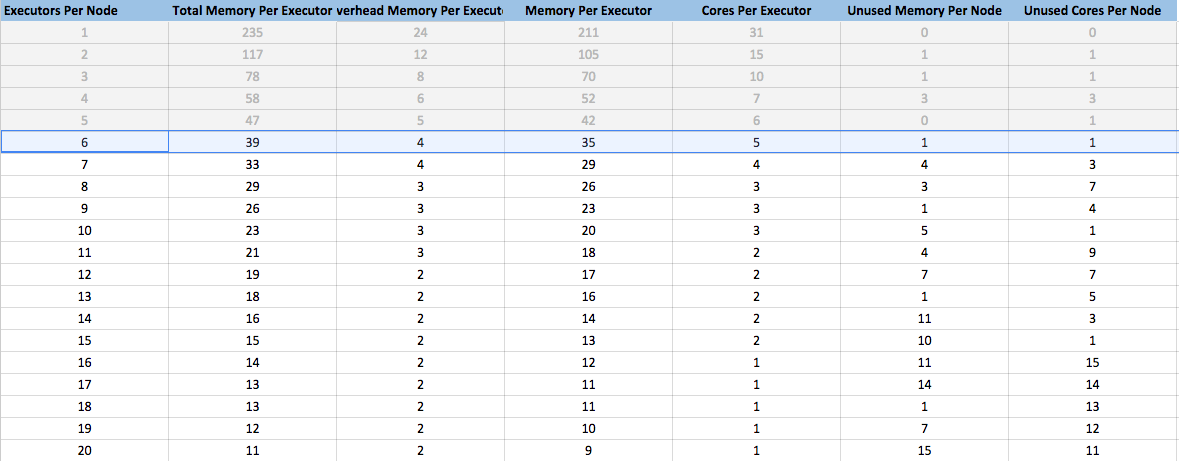
Once the configurable fields on the left-hand side of the spreadsheet have been set to the desired values, the resultant cluster configuration will be reflected in the reference table.
There is some degree of subjectivity in selecting the Executors Per Node setting that will work best for your use case, so I elected to use a reference table rather than selecting the number automatically.
A good rule of thumb for selecting the optimal number of Executors Per Node would be to select the setting that minimizes Unused Memory Per Node and Unused Cores Per Node while keeping Total Memory Per Executor below the Executor Memory Upper Bound and Core Per Executor below the Executor Core Upper Bound.
For example, take the reference table shown above:
- Executors Per Node: 1
- Unused Memory Per Node: 0
- Unused Cores Per Node: 0
Warning: Total Memory Per Executor exceeds the Executor Memory Upper BoundWarning: Cores Per Executor exceeds Executor Core Upper Bound- (That row has been greyed out since it has exceeded one of the upper bounds)
- Executors Per Node: 5
- Unused Memory Per Node: 0
- Unused Cores Per Node: 1
Warning: Cores Per Executor exceeds the Executor Core Upper Bound.
- Executors Per Node: 6
- Unused Memory Per Node: 1
- Unused Core Per Node: 1
- Total Memory Per Executor and Cores Per Executor are both below their respective upper bounds.
- Executors Per Node: All others
- Either exceed the Executor Memory Upper Bound, exceed the Executor Cores Upper Bound, or waste more resources than Executors Per Node = 6
Executors Per Node = 6 is the optimal setting.
Spark Configs

Now that we have selected an optimal number of Executors Per Node, we are ready to generate the Spark configs with which we will run our job. We enter the optimal number of executors in the Selected Executors Per Node field. The correct settings will be generated automatically.
spark.executor.instances (different for client mode)
(Number of Nodes * Selected Executors Per Node)
This is the number of total executors in your cluster. Unlike in cluster mode, we DO NOT subtract one to allow for the driver since it will not be running on one of our worker nodes.
spark.yarn.executor.memoryOverhead
Equal to Overhead Memory Per Executor
The memory to be allocated for the memoryOverhead of each executor, in MB. Calculated from the values from the row in the reference table that corresponds to our Selected Executors Per Node.
spark.executor.memory
Equal to Memory Per Executor
The memory to be allocated for each executor. Calculated from the values from the row in the reference table that corresponds to our Selected Executors Per Node.
spark.yarn.driver.memoryOverhead (different for client mode)
Master Memory * Memory Overhead Coefficient
The memory to be allocated for the memoryOverhead of the driver, in MB. In client mode, this value is usually lower than the spark.yarn.executor.memoryOverhead
spark.driver.memory (different for client mode)
Master Memory * (1 - Memory Overhead Coefficient)
The memory to be allocated for the driver. In client mode, this will usually be lower than the spark.executor.memory
spark.executor.cores
Equal to Cores Per Executor
The number of cores allocated for each executor. Calculated from the values from the row in the reference table that corresponds to our Selected Executors Per Node.
spark.driver.cores (different for client mode)
Master Cores - OS Reserved Cores
The number of cores allocated for the driver. In client mode, this will usually be lower than the spark.executor.cores
spark.default.parallelism
spark.executor.instances * spark.executor.cores * Parallelism Per Core
Default parallelism for Spark RDDs, Dataframes, etc.
Using Configs
As with the cluster mode configs, the client mode configs can be used in three different ways:
Add to spark-defaults.conf
Note: Will be used for submitted jobs unless overwritten by spark-submit args
spark.executor.instances 18
spark.yarn.executor.memoryOverhead 4096
spark.executor.memory 35G
spark.yarn.driver.memoryOverhead 3072
spark.driver.memory 26G
spark.executor.cores 5
spark.driver.cores 3
spark.default.parallelism 180
Pass as software settings to an AWS EMR Cluster
Note: Will be added to spark-defaults.conf
{
"Classification": "spark-defaults",
"Properties": {
"spark.executor.instances": "18",
"spark.yarn.executor.memoryOverhead": "4096",
"spark.executor.memory": "35G",
"spark.yarn.driver.memoryOverhead": "3072",
"spark.driver.memory": "26G",
"spark.executor.cores": "5",
"spark.driver.cores": "3",
"spark.default.parallelism": "180"
}
}
Pass as args with spark-submit
./bin/spark-submit \
--[your class] \
--master yarn \
--deploy-mode client \
--num-executors 18 \
--conf spark.yarn.executor.memoryOverhead=4096 \
--executor-memory 35G \
--conf spark.yarn.driver.memoryOverhead=3072 \
--driver-memory 26G \
--executor-cores 5 \
--driver-cores 3 \
--conf spark.default.parallelism=180 \
/path/to/examples.jar